
Quando si parla di web marketing in generale e di SEO in particolare, si incontrano termini e sigle che possono essere di difficile comprensione. Specie se si sta tentando di far capire a un potenziale cliente di cosa ci occupiamo, su cosa andremo a intervenire e quali sono i dati importanti.
In questo primo articolo forniremo un breve dizionario per imparare a spiegarci meglio con chi non fa questo mestiere.
Cos’è la SEO
Cominciamo con la sigla più facile e al contempo più difficile. Letteralmente parliamo di Search Engine Optimization, ovvero ottimizzazione per i motori di ricerca. Fattivamente questa attività comprende molteplici elementi che prendono in considerazione il codice di un sito, la sua organizzazione e i contenuti che ospita. Seppure generalmente si faccia riferimento a Google come motore di ricerca, in realtà i principi SEO sono applicabili a tutti i motori di ricerca, compresi quelli interni a grandi store come Amazon o eBay. Ognuno di essi ha delle proprie logiche, che vanno analizzate e studiate e sulle quali ci si può specializzare.
Oggi si parla anche di un passaggio da SEO a SXO, ovvero Search Experience Optimization, un’ottica che pone al centro dell’attenzione l’esperienza dell’utente, poiché ottimizzare un sito web significa entrare nella testa di chi lo utilizzerà, per aiutarlo a comprendere il messaggio che vogliamo fornirgli e dargli la risposta più adeguata all’esigenza che ha espresso.
Algoritmo
L’algoritmo è una complessa funzione matematica che consente al motore di ricerca di funzionare e fornire dei risultati a fronte di una richiesta, detta query. Quando digitiamo una richiesta su Google stiamo interrogando l’algoritmo, chiedendogli di darci una risposta. L’algoritmo si basa su molteplici fattori, per Google si parla di oltre 200, sono segreti e soprattutto variano di importanza a seguito di importanti aggiornamenti che vengono rilasciati dagli ingegneri che se ne occupano.
Crawler
Il crawler, o anche spider e robot, è un programma di proprietà del motore di ricerca, che scansiona i siti web, leggendone le caratteristiche. La frequenza con cui un crawler visita un sito web è variabile ed è possibile anche indicare che alcune pagine non devono essere tenute in considerazione. Quest’ultima operazione si fa attraverso il file robots.txt.
Google Search Console
Si tratta del vecchio Webmaster Tools, ovvero un insieme di strumenti messi a disposizione da Google in maniera gratuita e dedicati al webmaster (e ai SEO). Da questa console possiamo segnalare la sitemap, controllare il robots, verificare i tag html, verificare le pagine di errore e molto altro. Quando si mette online un sito è importante che venga attivata anche la Search Console.
HTTP status code
I codici di stato indicano la versione del server e un numero di 3 cifre che identifica lo Status in cui si trova la pagina. Si suddividono in base al numero iniziale:
- Status code che iniziano per 1: la risposta è provvisoria
- Status code che iniziano per 2: la richiesta è stata ricevuta e viene elaborata correttamente. Fra questi c’è lo status code 200 che indica che la richiesta http è andata a buon fine.
- Status code che iniziano per 3: sono necessarie ulteriori operazioni per soddisfare la richiesta. Fra questi ci sono lo staus code 301 che indica la presenza di un redirect permanente da una risorsa a un’altra e lo status code 302, che indica un redirect temporaneo da una risorsa all’altra.
- Status code che iniziano per 4: la richiesta non può essere soddisfatta. Tra questi c’è lo status code 404 che indica una pagina non trovata.
- Status code che iniziano per 5: il server non riesce a soddisfare una richiesta valida. Tra questi ci sono lo status code 500 che indica un errore interno al server e il 503 che indica un’indisponibilità temporanea del server.
Gli errori 404 e 500 vengono indicati anche nella Search Console e vanno analizzati per identificare eventuali correzioni da apportare, al fine di migliorare l’esperienza dell’utente.
Indicizzazione e posizionamento
È una questione di fronte a cui ci si trova spesso. Il cliente chiede l’indicizzazione, noi sappiamo che parla di posizionamento. L’indicizzazione avviene quando il motore di ricerca viene a conoscenza dell’esistenza di una pagina web e la inserisce nel suo database, ciò avviene più o meno naturalmente e, a meno di blocchi particolari, tutte le pagine di un sito prima o poi vengono indicizzate.
Quello che si richiede a chi fa SEO è il posizionamento. Ovvero aiutare una pagina web a essere tra le prime posizioni dei risultati di ricerca a fronte di una query interessante digitata dall’utente.
Operatori del motore di ricerca
Quando facciamo una ricerca su Google tendiamo a scrivere semplicemente ciò che ci occorre, in realtà esistono alcuni operatori che consentono di approfondire la ricerca e renderla più specifica.
- Molto utile è il site (site:www.nomesito.tld) che ci mostra tutte le pagine indicizzate di un dato dominio o tutte le pagine di un dominio il cui URL inizia con una certa directory (es. site:www.nomesito.tld/category). Non sempre questo operatore è accurato, potrebbe omettere alcuni risultati, ma in fase di analisi fornisce un’idea di massima delle pagine indicizzate.
- Gli operatori inurle allinurl (es. inurl:seo) ci indicano tutti gli URL che contengono una certa parola.
- Gli operatori intitlee allintitle (es. intitle:seo) ci indicano tutte le pagine che hanno nel ta title una parola data.
- Gli operatori inanchore allinanchor ci mostrano gli URL che hanno backlink con anchor text la parola data. Con inanchor troviamo quelli che hanno la maggior parte dei backlink con un certo anchort text, con allinanchor tutte le pagine che hanno backlink con un determinato anchor text.
- L’operatore intext analizza solo il body della pagina e ci mostra quelle che hanno più occorrenze rlative al termine dato.
- Gli operatori ext e filetype ci aiutano a trovare i file presenti nel sito con una certa estensione (es. filetype:pdf)
Tutti gli operatori possono essere combinati fra loro per raffinare le ricerche. Per una lista completa fare riferimento alla guida di Moz.
Query e keyword
Una query è una domanda che viene posta a un database, nel caso del motore di ricerca tutte le ricerche che digitiamo sono query che interrogano l’immenso database di Google.
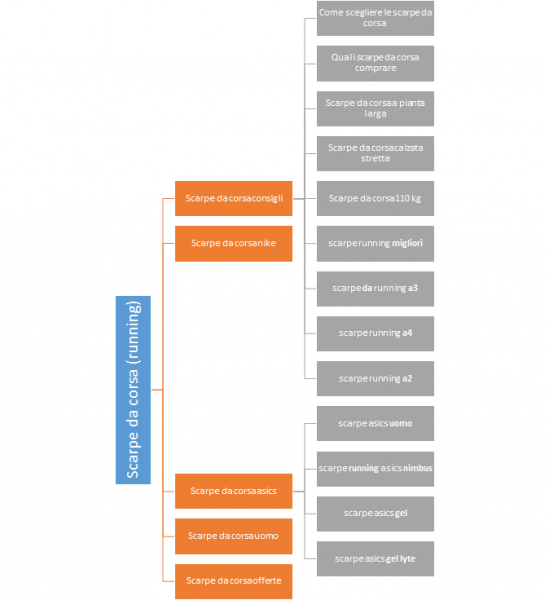
Le keyword che vengono scelte per l’ottimizzazione di un sito dipendono dalle query. Le parole chiave derivano da un’analisi che viene effettuata sulle ricerche digitate dagli utenti, con lo scopo di identificare quelle che rappresentino il senso che si trova in ciascuna query. Hummingbird, uno degli aggiornamenti dell’algoritmo di Google, ha modificato la precedente concezione di keyword, spostandola su un lato più semantico. Se andiamo ad analizzare le ricerche correlate che Google ci propone possiamo cogliere meglio il senso di questo cambiamento. Nell’esempio che segue potremo vedere che le scarpe da corsa sono equiparate alle scarpe da running e che gli utenti cercano in base a sesso, marchio, prezzo e anche in base a informazioni più specifiche, che possono suggerirci nuovi argomenti da trattare nel nostro sito/blog. Quindi se il mio sito vende scarpe da corsa dovrò categorizzare i prodotti per brand, sesso, prezzo, modello di ogni brand e potrebbe essere utile creare una sezione di approfondimento dove fornisco consigli su quali scarpe da running acquistare.
Robots.txt
Si tratta di un semplice file, di pochi kb, che viene caricato nella root del sito. Contiene molteplici informazioni e dovrebbe essere sempre presente. Tramite il robots possiamo indicare l’indirizzo della sitemap xml, ma soprattutto possiamo indicare quali sono le risorse bloccare per i vari crawler ed evitarne quindi l’indicizzazione. Ad esempio, quando è presente un’area riservata è importante bloccarne l’indicizzazione attraverso il robots.
SERP
La SERP – Search Engine Results Page – è la pagina dei risultati di ricerca. Solitamente si usano espressioni del tipo “La pagina è in 15^ posizione della SERP per la query vattelappesca”.
Attualmente la SERP di Google include, oltre alle pagine web tradizionali, anche immagini, video, mappe e tutto ciò che può fornire maggiori informazioni per l’utente. Se, ad esempio, cerchiamo il nome di un attore, troveremo sulla destra (da desktop) la sua filmografia, le ricerche correlate e parte della sua biografia.
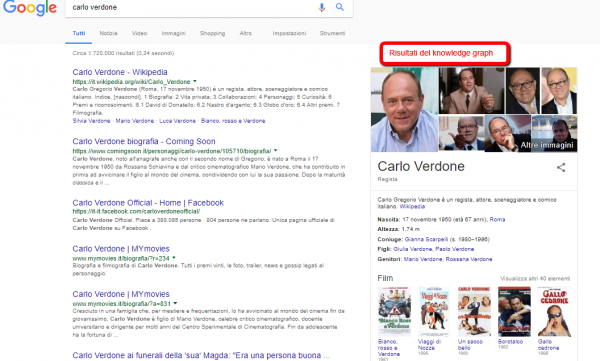
Ciò accade dal 2012, quando Google introdusse il Knowledge Graph, ovvero il primo passo verso una ricerca più semantica e meno orientata alle keyword specifiche.
Sitemap xml
La sitemap xml è una mappa del sito, scritta in linguaggio xml, che fornisce al motore di ricerca l’elenco di tutte le risorse che compongono il sito, indicandone l’ultimo aggiornamento. Se una pagina è bloccata da robots non deve essere nella sitemap, se una pagina è una 404 non deve essere nella sitemap ecc… In poche parole la sitemap deve contenere solo le pagine che vogliamo che il motore di ricerca veda. Possiamo creare degli indici di sitemap, in maniera da creare file più leggeri e facilmente scansionabili, ma soprattutto così possiamo dividere i vari tipi di risorse, distinguendo sitemap per testi, immagini, video e così via. Una volta creata la sitemap xml deve essere segnalata al motore di ricerca, per Google si usa Search Console.
Tag HTML
I tag HTML sono marcatori che identificano il ruolo di un dato elemento all’interno di una pagina web. Ogni tag è composto da:
- un tag di apertura che definisce l’inizio di un elemento (es. <p>);
- uno o più attributi di tale elemento con i loro rispettivi valori (es. <p style=”font-size:12px”>;
- il contenuto informativo da visualizzare (es.<p>testo da mostrare</p>;
- un tag di chiusura che è opzionale per molti elementi (es. </p>).
Nella SEO uno dei tag più importanti è il tag title (<title>testo</title>) che si trova nell’head della pagina e che dovrebbe essere accompagnato dal metatag description (<meta name=”description” content=”descrizione della pagina”/>).

Ci sono poi gli headings (h1, h2, h3, h4, h5, h6) che definiscono la gerarchia di titoli e sottotitoli in una pagina. Come best practice è bene avere un solo H1 in ciascuna pagina, seppure l’introduzione dell’HTML5 abbia creato una deroga a questa regola, consentendo di utilizzare un H1 per ciascuna sezione della pagina.
Ce ne sono moltissimi altri che avremo occasione di analizzare in articoli successivi.